LLM optimizations
Optimizing the attention mechanism
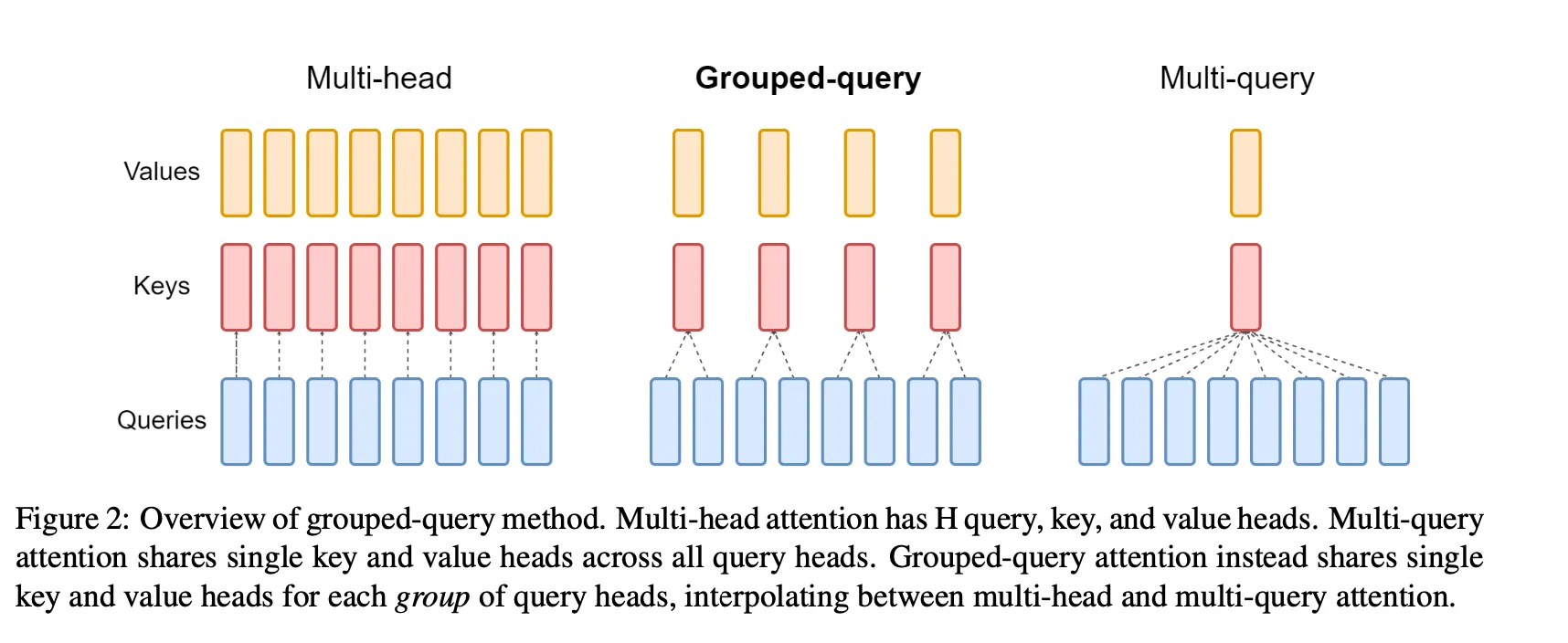
Multi-query attention
Multi-query attention (MQA) shares the keys and values among all the attention heads. The query vector is still projected multiple times, as before, but there is one set of keys and values for all heads. While the amount of computation done in MQA is identical to multi-head attention, the amount of data (keys, values) read from memory is a fraction of before. When bound by memory-bandwidth, this enables better compute utilization. It also reduces the size of the KV-cache in memory, allowing space for larger batch sizes.
Grouped-query attention
Grouped-query attention (GQA) projects keys and values to a few groups of query heads. It has more key-value heads than one, but fewer than the number of query heads. It’s a balance between multi-head attention and multi-query attention.
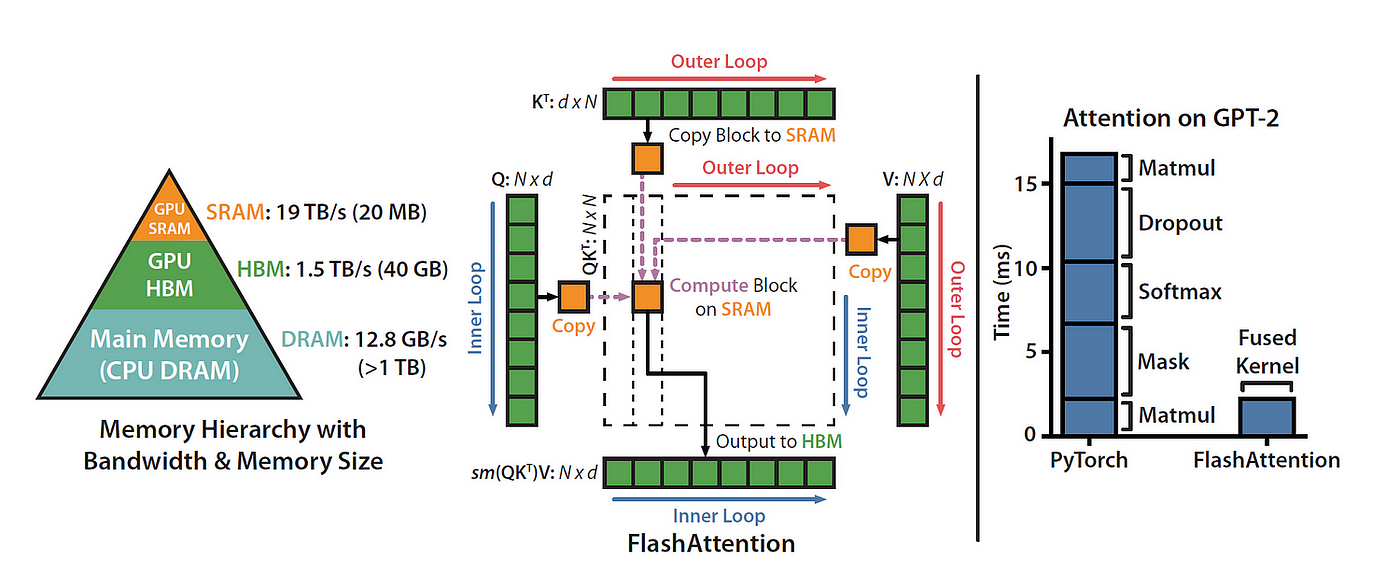
Flash attention
We can also optimize the attention mechanism by reordering certain computations to make better use of the GPU’s memory hierarchy. Neural networks are usually organized by layers, and most implementations follow this structure, with each type of computation applied in sequence to the input data. However, this layer-by-layer approach isn’t always the most efficient. Often, it’s more effective to perform additional calculations on data that’s already loaded into the higher, faster levels of GPU memory.
By combining multiple layers during computation, we can reduce the number of times the GPU has to read from and write to its memory. This also lets us group calculations that need the same data, even if they come from different layers in the network. This fusion of operations can lead to more efficient processing overall.
FlashAttention is an I/O aware exact attention algorithm.
I/O aware means it takes into account some of the memory movement costs previously discussed when fusing operations together. In particular, FlashAttention using “tiling” to fully compute and write out a small part of the final matrix at once, rather than doing part of the computation on the whole matrix in steps, writing out the intermediate values in between.
Exact attention means that it is mathematically identical to the standard multi-head attention (with variants available for multi-query and grouped-query attention), and so can be swapped into an existing model architecture or even an already-trained model with no modifications.
Modifications to model weights
Quantization
Quantization is the process of reducing the precision of a model’s weights and activations. Most models are trained with 32 or 16 bits of precision, where each parameter and activation element takes up 32 or 16 bits of memory - a single-precision floating point. However, most deep learning models can be effectively represented with eight or even fewer bits per value.
Sparsity
Similar to quantization, it’s been shown that many deep learning models are robust to pruning, or replacing certain values that are close to 0 with 0 itself. Sparse matrices are matrices where many of the elements are 0. These can be expressed in a condensed form that takes up less space than a full, dense matrix.
Distillation
This process involves training a smaller model that’s called a student model to mimic the behavior of the larger model (the teacher model). The student model will be trained to mirror the performance of the teacher model, with a loss function that measures the discrepancy between their outputs. DistilBERT compresses a BERT model by 40% while retaining 97% of its language understanding capabilities at a 60% faster speed. –>