FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Dao et al., arXiv:2205.14135
Paper Abstract
Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to address this problem by trading off model quality to reduce the compute complexity, but often do not achieve wall-clock speedup. We argue that a missing principle is making attention algorithms IO-aware—accounting for reads and writes between levels of GPU memory. We propose FlashAttention, an IO-aware exact attention algorithm that uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM. We analyze the IO complexity of FlashAttention, showing that it requires fewer HBM accesses than standard attention, and is optimal for a range of SRAM sizes. We also extend FlashAttention to block-sparse attention, yielding an approximate attention algorithm that is faster than any existing approximate attention method. FlashAttention trains Transformers faster than existing baselines: 15% end-to-end wall-clock speedup on BERT-large (seq. length 512) compared to the MLPerf 1.1 training speed record, 3× speedup on GPT-2 (seq. length 1K), and 2.4× speedup on long-range arena (seq. length 1K-4K). FlashAttention and block-sparse FlashAttention enable longer context in Transformers, yielding higher quality models (0.7 better perplexity on GPT-2 and 6.4 points of lift on long-document classification) and entirely new capabilities: the first Transformers to achieve better-than-chance performance on the Path-X challenge (seq. length 16K, 61.4% accuracy) and Path-256 (seq. length 64K, 63.1% accuracy).
Attention hurts on long sequences
- Self-attention costs \(O(L^2)\) in time and memory in sequence length \(L\): the attention matrix materializes the pairwise interactions.
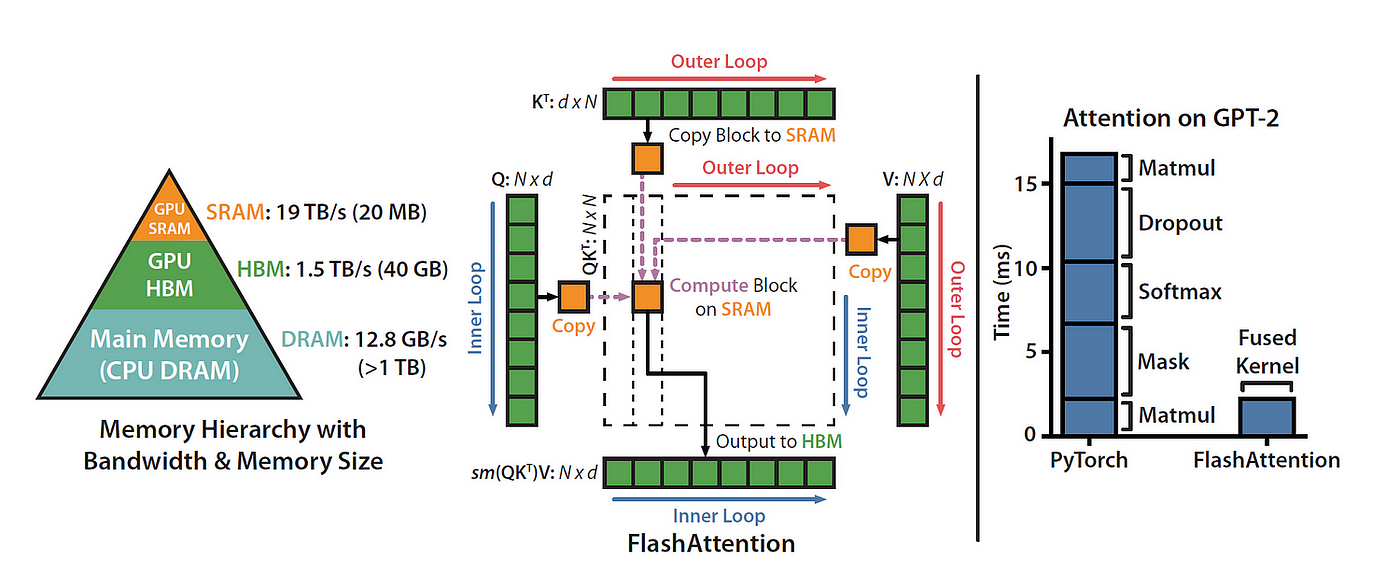
- FlashAttention’s thesis: the real bottleneck on modern GPUs is often not FLOPs but memory traffic between slow HBM (high bandwidth memory, off-chip) and fast on-chip SRAM—so algorithms should be IO-aware: count reads/writes across the memory hierarchy, not just arithmetic.
Approximate attention
- Many approximate methods (sparse, low-rank, combinations) cut asymptotic compute toward linear / near-linear in \(L\).
- But many still don’t show wall-clock speedups vs standard attention and haven’t been widely adopted.
- One reason: they optimize FLOP counts, which don’t track real runtime when the kernel is memory-bound; they underweight IO and memory-access overhead.
- This paper: make attention IO-aware—explicitly account for traffic between fast on-chip SRAM and slower HBM.
GPUs are often memory-bound
- Compute has scaled faster than memory bandwidth; many Transformer ops are limited by moving data, not by arithmetic.
- IO-aware algorithms matter in other domains too (joins, imaging, classical LA), but PyTorch / TensorFlow abstractions usually don’t expose fine-grained control over memory access patterns—hence a custom CUDA implementation for FlashAttention.
What FlashAttention targets
- Compute exact attention (same outputs as the naive formulation) with far fewer round-trips to HBM.
- Main goal: avoid materializing the full attention matrix in HBM (both for reads and writes).
That forces two technical problems:
- Softmax without seeing the full input at once — you can’t load the entire score matrix into SRAM.
- Backward without storing the large intermediate attention matrix in HBM for the backward pass.
Their technique
Softmax / tiling
- Restructure attention: tile the problem—split tensors into blocks and make multiple passes over blocks, incrementally completing the softmax normalization (online softmax / blocked reduction).
Backward / recomputation
- In the forward pass, store the softmax normalization statistics (what you need to reconstruct local pieces).
- On the backward pass, recompute attention-related values on-chip from those statistics instead of reading a huge attention matrix back from HBM (recompute can be cheaper than HBM traffic).
Implementation
- CUDA implementation for fine-grained memory control and to fuse the attention steps into one (or few) kernels.
- Even with extra FLOPs from recomputation, the method can be faster (fewer slow-memory round-trips) and use \(O(L)\) memory in sequence length for the attention block vs materializing \(O(L^2)\) in HBM.