Transformer Architecture
The transformer is made up of an encoder block and a decoder block.
The encoder’s role is to process the input sequence in its entirety and distill it into a condensed vector representation. The encoder consits of a series of N=6 identical layers, each containing two principle sub-layers: a multi-head self-attention mechanism and a position-wise fully connected feed-forward network.
The decoder’s role is output generation. It does this sequentially (next token prediction). The decoder also consists of N=6 identical layers. However, it includes an additional third sub-layer that facilitates multi-head attention over the encoder’s output.
Encoder In-Depth
- each word/token in the input sentence is converted into a dense vector using token embeddings
- positional encoding is added to each embedding to provide positional information. The Transformer architecture doesn’t account for sequence order, so this is necessary.
- each token embedding is linearly transformed into a query, key, and value vector through learned weight matrices. We have three parameter matrices W, K, V that we will train during training time and multiplying each of these by the input token will let us get the query, key, and value vectors.
- the model computes the dot product between each token’s query vector and each token’s key vector in the sequence to calculate attention scores. This score gives a similarity score that reflects how much attention the two tokens should give each other.
- we follow with a scaling and applying a softmax to these scores and then multiplying by the value vectors to get a weighted sum of all value vectors
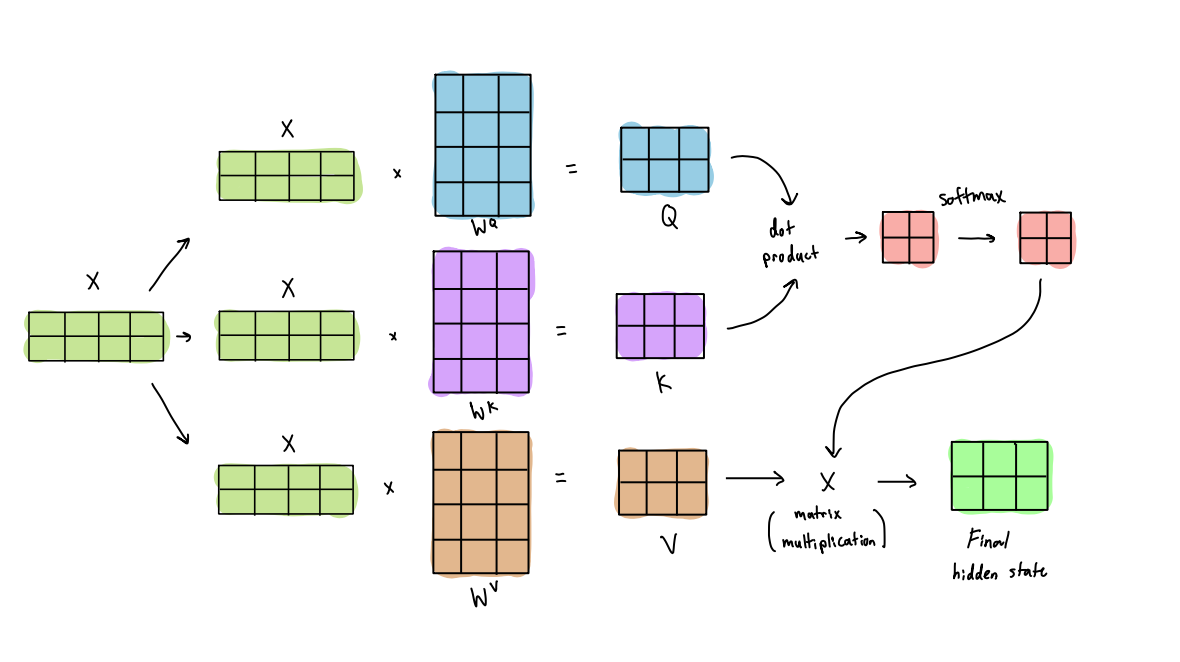
- we then pass this output through a feed-forward neural network
- we stack 6 or more of these encoder layers together to form the entire encoder block
Decoder In-Depth
- convert the input tokens (which are the output tokens of the encoder so far) into token embeddings
- similar to the encoder block, we also apply positional encoding to the token embeddings
- the self-attention mechanism is applied with a masking mechanism to maintain that the decoder can only attend to earlier positions in the output sequence
- a second attention mechanism: now the Q vector comes from the decoder’s previous layer but K and V come from the encoder’s output. This attention mechanism allows the decoder to focus on relevant parts of the input sentence.
- the output of the encoder-decoder attention goes through a feed-forward network
- we stack 6 or more of these decoder layers together to form the entire decoder block
Positional Encodings
Here’s a quick walkthrough on how positional encodings work and why we need them. We add positional encodings in step 2 of both the encoder and decoder step to provide positional information to the model based on each token’s relative position in the sequence. Unlike RNNs or LSTMs which process tokens sequentially, transformers process all tokens at once and so they don’t have the same built-in notion of the sense of order of token positions relative to each other.
Positional encodings use fixed sine and cosine functions. For each token position pos and each dimension i of the embedding, the positional encoding PE(pos, i) are calculated as follows:
For even dimensions (2i):
\(PE(pos, 2i) = \sin\left(\frac{pos}{10000^{\frac{2i}{d}}}\right)\)
For odd dimensions (2i+1):
\(PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{\frac{2i}{d}}}\right)\)
After we calculate these positional encodings for each token embedding, we add these positional encodings directly to the embeddings for each token. This combines positional information with the original semantic meaning of each word.
Here’s a step-by-step example. Let’s assume the input sequence is “I love transformers”

Now we just feed these three resulting vectors into the encoder or decoder block.